第三方免費(fèi)做網(wǎng)站seo云優(yōu)化公司
前言:本文就前期學(xué)習(xí)快速排序算法的一些疑惑點(diǎn)進(jìn)行詳細(xì)解答,并且給出基礎(chǔ)快速排序算法的優(yōu)化版本
一.再談快速排序
快速排序算法的核心是分治思想,分治策略分為以下三步:
- 分解:將原問(wèn)題分解為若干相似,規(guī)模較小的子問(wèn)題
- 解決:如果子問(wèn)題規(guī)模較小,直接解決;否則遞歸解決子問(wèn)題
- 合并:原問(wèn)題的解等于若干子問(wèn)題解的合并
應(yīng)用到快速排序算法:
- 分解:快速排序算法要實(shí)現(xiàn)的是對(duì)整個(gè)數(shù)組進(jìn)行排序,但是規(guī)模較大,要想辦法減少規(guī)模;他的解決策略是"選擇一個(gè)基準(zhǔn)元素,將數(shù)組劃分為兩部分,左邊都是小于基準(zhǔn)元素,右邊都是大于基準(zhǔn)元素",不斷的重復(fù)上述過(guò)程,就能完成對(duì)整個(gè)數(shù)組的排序.對(duì)整個(gè)數(shù)組完成一次這樣的操作后,再對(duì)左右兩個(gè)區(qū)間分別執(zhí)行上述過(guò)程
- 遞歸地對(duì)兩個(gè)子數(shù)組進(jìn)行快速排序,直到每個(gè)子數(shù)組的長(zhǎng)度為0或1,此時(shí)數(shù)組已經(jīng)有序。
- 由于在遞歸過(guò)程中子數(shù)組已經(jīng)被分別排序,因此不需要再進(jìn)行額外的合并步驟。
二.代碼實(shí)現(xiàn)和細(xì)節(jié)講解
快速排序的關(guān)鍵代碼在于如何根據(jù)基準(zhǔn)元素劃分?jǐn)?shù)組區(qū)間(parttion),分解的方法有很多,這里只提供一種方法挖坑法
代碼:
class Solution {public int[] sortArray(int[] nums) {quick(nums, 0, nums.length - 1);return nums;}private void quick(int[] arr, int start, int end) {if(start >= end) return;// 遞歸結(jié)束條件int pivot = parttion(arr, start, end);// 遞歸解決子問(wèn)題quick(arr, start, pivot - 1);quick(arr, pivot + 1, end);}// 挖坑法進(jìn)行分解private int parttion(int[] arr, int left, int right) {int key = arr[left];while(left < right) {while(left < right && arr[right] >= key) right--;arr[left] = arr[right];while(left < right && arr[left] <= key) ++left;arr[right] = arr[left];}arr[left] = key;return left;}}
細(xì)節(jié)解答:
1.為什么start>=end是遞歸結(jié)束條件?
不斷的分解子問(wèn)題,最終子問(wèn)題的規(guī)模大小是1,即只有一個(gè)元素,此時(shí)無(wú)需繼續(xù)進(jìn)行分解,start和end指針同時(shí)指向該元素
2.為什么要right先走?而不是left先走?
具體誰(shuí)先走取決于
基準(zhǔn)元素的位置,在上述代碼中,基準(zhǔn)元素(key)是最左邊的元素,如果先移動(dòng)left,left先遇到一個(gè)比基準(zhǔn)元素大的元素,此時(shí)執(zhí)行arr[right] = arr[left],由于沒(méi)有保存arr[right],這個(gè)元素就會(huì)丟失
如果先走right,right先遇到一個(gè)比基準(zhǔn)元素小的元素,此時(shí)執(zhí)行arr[left]=arr[right],因?yàn)榇藭r(shí)left并沒(méi)有移動(dòng),還是pivot,但是pivot已經(jīng)被我們使用key進(jìn)行保存了
3.為什么是arr[right]>=key?>不行嗎
大于等于主要是為了處理
重復(fù)元素問(wèn)題
例如有數(shù)組[6,6,6,6,6]如果是>,right指針不會(huì)發(fā)生移動(dòng),left指針也不會(huì)發(fā)生移動(dòng),此時(shí)陷于死循環(huán)
4.為什么叫做挖坑法
當(dāng)r指針遇到第一個(gè)<pivot的元素后停止,執(zhí)行
arr[r] = arr[l],此時(shí)l位置就空白出來(lái),形成了一個(gè)坑
三.快速排序的優(yōu)化
主要有兩個(gè)優(yōu)化方向:
- 基準(zhǔn)值pivot的選取,可以證明的是當(dāng)隨機(jī)選取基準(zhǔn)值時(shí),快速排序的時(shí)間復(fù)雜度趨近于
O(N*logN),即最好的時(shí)間復(fù)雜度 - 重復(fù)元素的處理:如果區(qū)間內(nèi)部有大量的重復(fù)元素,上述版本的快速排序算法會(huì)對(duì)相同的元素重復(fù)執(zhí)行多次;為了減少冗余的操作,使用
數(shù)組分三塊的思想解決,同時(shí)如果遇到特殊的測(cè)試用例(順序數(shù)組或逆序數(shù)組)時(shí)間復(fù)雜度會(huì)退化到O(N^2)
先根據(jù)一道題目(顏色分類(lèi))了解什么是數(shù)組分三塊
分析
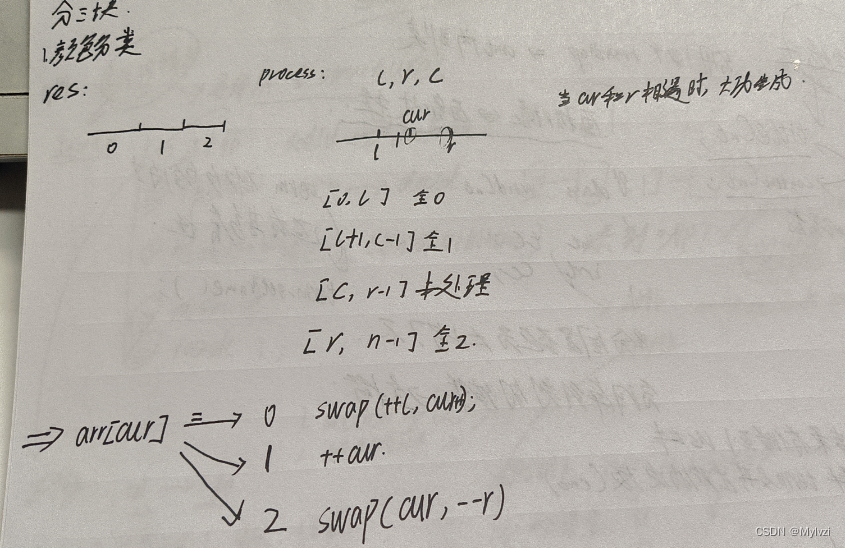
代碼:
class Solution {public void sortColors(int[] nums) {// 分治 --// 1.定義三指針int i = 0;// 遍歷整個(gè)數(shù)組int l = -1, r = nums.length;while(i < r) {if(nums[i] == 0) swap(nums,++l,i++);else if(nums[i] == 1) i++;else swap(nums,--r,i);}return;}private void swap(int[] nums,int x,int y) {int tmp = nums[x]; nums[x] = nums[y]; nums[y] = tmp;}
}
- 注意
l,r的起始位置,第一個(gè)元素和最后一個(gè)元素在開(kāi)始的時(shí)候?qū)儆?code>未處理狀態(tài),所以`l,r不能指向這兩個(gè)元素,必須在區(qū)間之外 - 所謂的數(shù)組分三塊,就是使用
三個(gè)指針去分別維護(hù)四個(gè)區(qū)間,其中的一個(gè)區(qū)間是未處理區(qū)間,隨著cur指針的不斷移動(dòng),所有的區(qū)間都被處理,最終也就只有三個(gè)區(qū)間
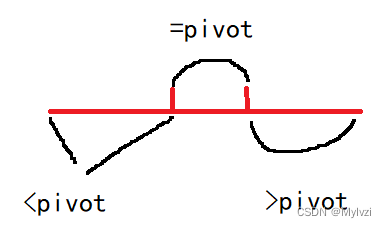
將上述思路應(yīng)用于快速排序的parttion中,最終的結(jié)果就是劃分為三個(gè)區(qū)間
代碼實(shí)現(xiàn):
class Solution {// 快速排序優(yōu)化版// 分解--解決--合并public int[] sortArray(int[] nums) {qsort(nums, 0, nums.length - 1);return nums;}private void qsort(int[] nums, int start, int end) {if(start >= end) return;// 遞歸結(jié)束條件// 分解int pivot = nums[start];int l = start - 1, r = end + 1, i = start;while(i < r) {int cur = nums[i];if(cur < pivot) swap(nums, ++l, i++);else if(cur == pivot) ++i;else swap(nums, --r, i);}// [start, l] [l+1, r-1] [r, end]// 遞歸解決qsort(nums, start, l);qsort(nums, r, end);}private void swap(int[] nums,int i, int j) {int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;}
}
2.隨機(jī)選取基準(zhǔn)值
采用隨機(jī)數(shù)的方式隨機(jī)選取基準(zhǔn)值
int pivot = nums[start + new Random().nextInt(end - start + 1)];// 起始位置 隨機(jī)產(chǎn)生的偏移量完整的改進(jìn)代碼:
class Solution {// 快速排序優(yōu)化版// 分解--解決--合并public int[] sortArray(int[] nums) {qsort(nums, 0, nums.length - 1);return nums;}private void qsort(int[] nums, int start, int end) {if(start >= end) return;// 遞歸結(jié)束條件// 分解int pivot = nums[start + new Random().nextInt(end - start + 1)];int l = start - 1, r = end + 1, i = start;while(i < r) {int cur = nums[i];if(cur < pivot) swap(nums, ++l, i++);else if(cur == pivot) ++i;else swap(nums, --r, i);}// [start, l] [l+1, r-1] [r, end]// 遞歸解決qsort(nums, start, l);qsort(nums, r, end);}private void swap(int[] nums,int i, int j) {int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;}
}

- 效率明顯提升
四.快速選擇算法
快速選擇算法是基于快速排序優(yōu)化版本的一種時(shí)間復(fù)雜度可達(dá)到O(N)的選擇算法,使用場(chǎng)景為第K大/前K大之類(lèi)的選擇問(wèn)題
01.數(shù)組中的第K個(gè)最大的元素
鏈接:https://leetcode.cn/problems/kth-largest-element-in-an-array/
分析
- 暴力解法就是直接使用
sort進(jìn)行排序,然后返回第K大即可 - 時(shí)間復(fù)雜度:
O(N*logN) - 空間復(fù)雜度:
O(logN)遞歸產(chǎn)生的棧調(diào)用
接下來(lái)采用快速選擇算法,實(shí)現(xiàn)O(N)的時(shí)間復(fù)雜度
代碼:
class Solution {public int findKthLargest(int[] nums, int k) {return qsort(nums, 0, nums.length - 1, k);}private int qsort(int[] nums, int start, int end, int k) {if(start >= end) return nums[start];int pivot = nums[start + new Random().nextInt(end - start + 1)];// 數(shù)組分三塊 <pivot ==pivot >pivotint l = start - 1, r = end + 1, i = start;while(i < r) {if(nums[i] < pivot) swap(nums, ++l, i++);else if(nums[i] == pivot) ++i;else swap(nums, --r, i);}// [start, l] [l+1, r - 1] [r, end]int c = end - r + 1, b = r - 1 - (l + 1) + 1, a = l - start + 1;// 分情況討論 進(jìn)行選擇if(c >= k) return qsort(nums, r, end, k);else if(b + c >= k) return pivot;else return qsort(nums, start, l, k - b - c);// 找較小區(qū)間的第(k-b-c)大}private void swap(int[] arr, int i, int j) {int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;}
}
- 快速選擇算法和快速排序的思想很像,不同點(diǎn)在于快速選擇算法只對(duì)每次parttion結(jié)果的一部分區(qū)間進(jìn)行遞歸,而不是像快速排序一樣對(duì)整個(gè)區(qū)間進(jìn)行遞歸,所以快速選擇算法的時(shí)間復(fù)雜度降到了
O(N)